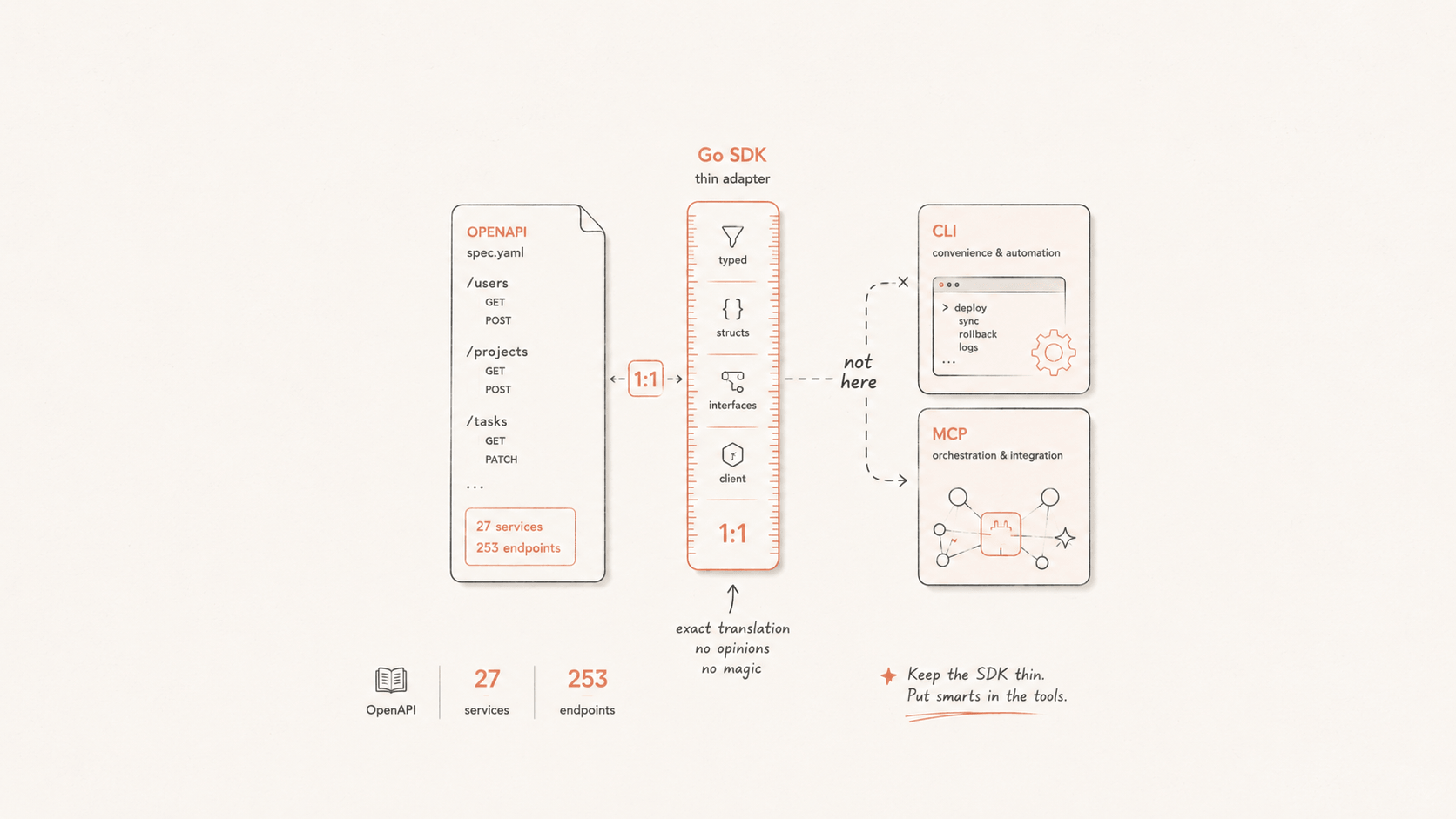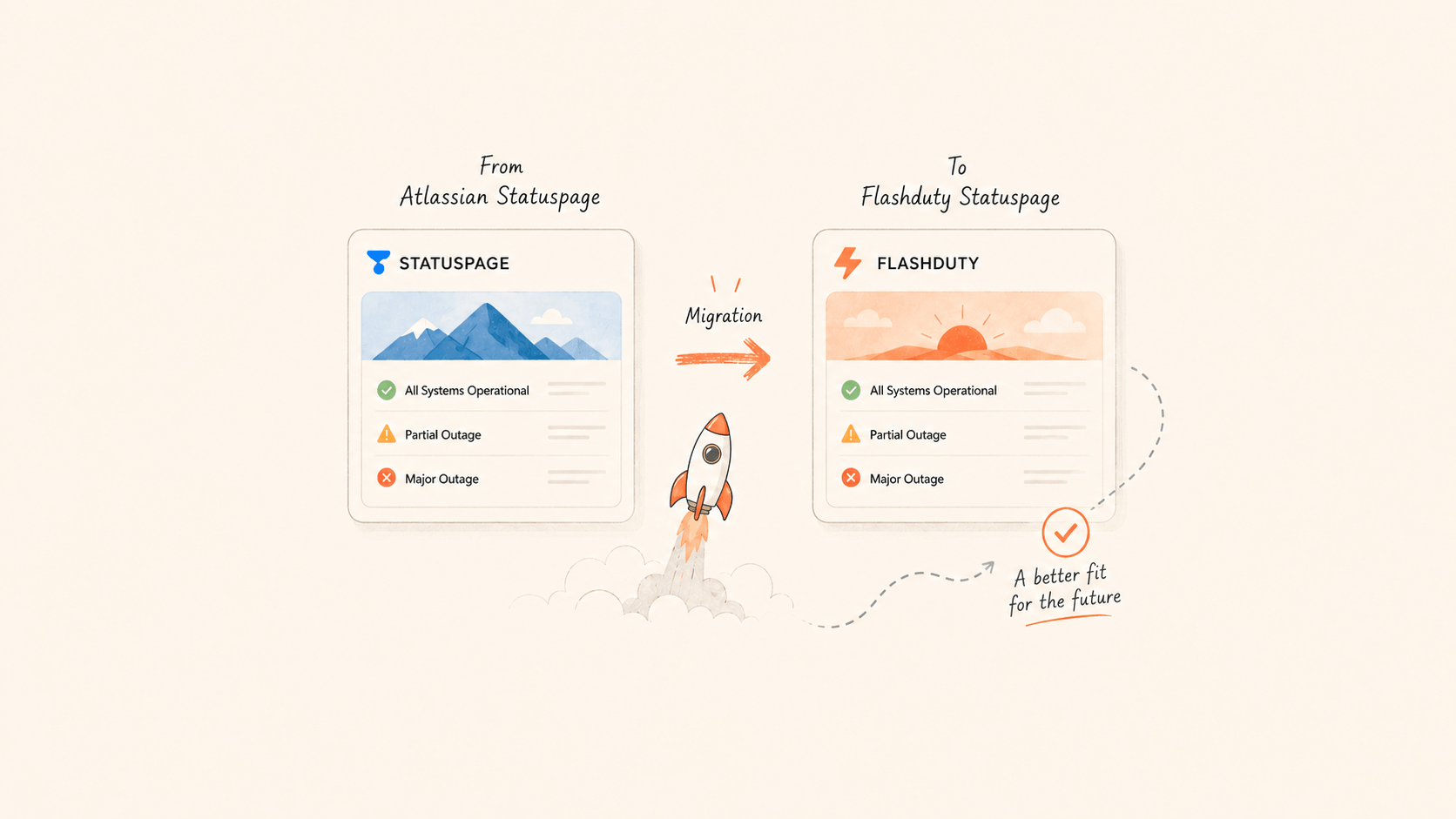
DeepSeek 换了状态页
DeepSeek 把公开状态页 status.deepseek.com 从 Atlassian Statuspage 换成了 Flashduty Statuspage。
状态页平时存在感很低。一旦服务抖了,外部还看得到的入口没几个,状态页通常是其中之一:用户会刷新,客户会转发,媒体也会看。这个页面不能只按“展示页”来选,它承担的是故障时的对外沟通。
这次迁移本身不稀奇,值得看的是影响选型的几笔账。
为什么换到 Flashduty
第一笔账是中文。
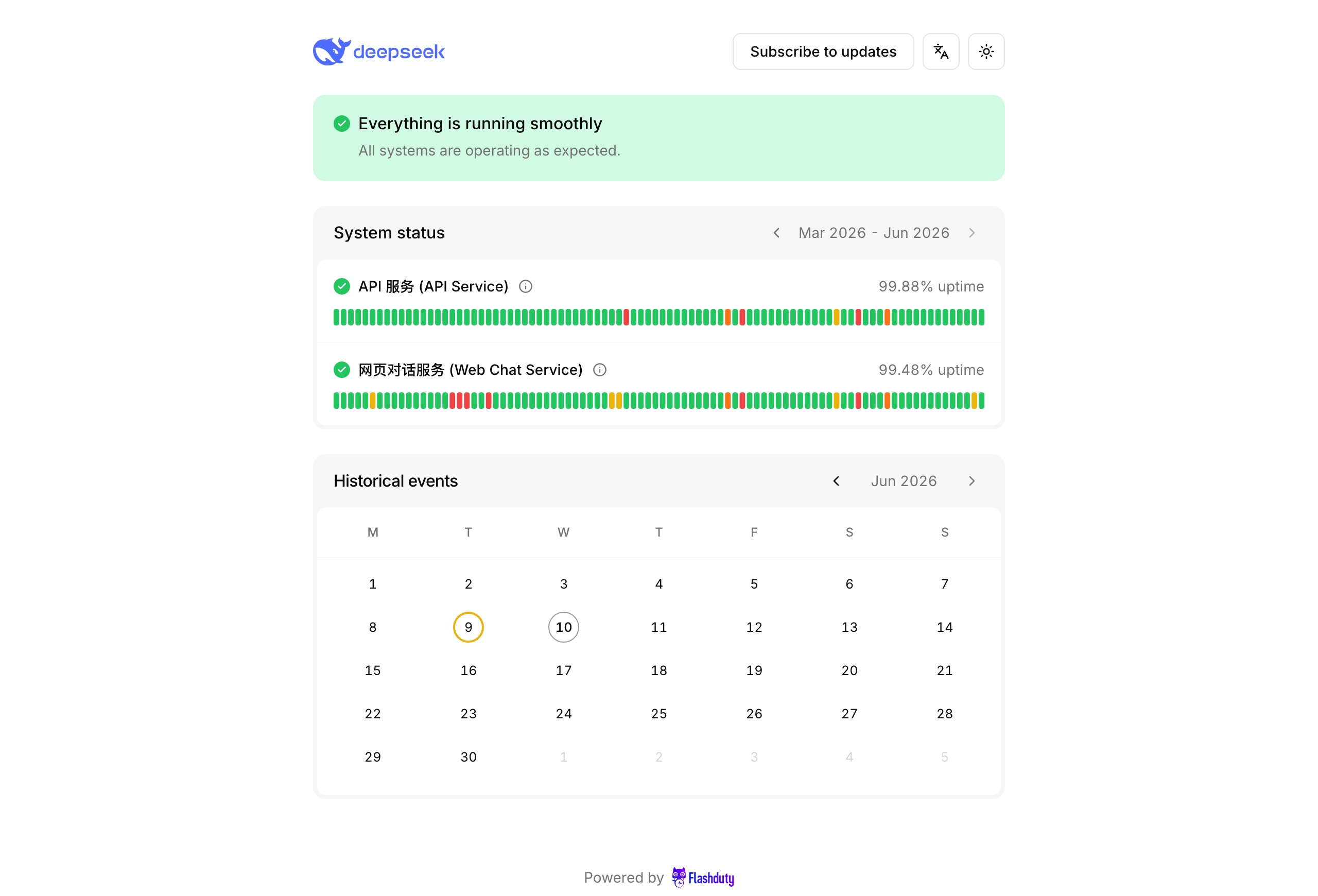
Atlassian Statuspage 的公开页没有原生中文,多语言要靠第三方本地化(比如 Localize)补一层。对 DeepSeek 这种用户大多看中文的服务来说,故障时让用户读纯英文状态页,体验上站不住。Flashduty 原生支持中文,页面有语言切换,组件名也可以写成「API 服务 (API Service)」这种中英并列,一个页面同时照顾国内外用户。
第二笔账是成本。Atlassian Statuspage 是单独产品,按订阅者、组件、团队成员分档收费。公开页加内部页,一年下来是几千美元的量级。Flashduty 状态页包含在 On-call 里,不单独收钱;如果团队已经在用 On-call,状态页就是同一套故障响应链路里的一个出口。剩下会按量产生的,主要是邮件推送费用。
还有页面本身。暗色模式、渲染性能、全球访问加速,这些现在已经是底线。DeepSeek 的状态页慢一点、糊一点,或者海外访问不稳,都会被放大。Flashduty 的状态页更接近今天用户对公开页面的预期,不是老式运维后台换个皮。
维护事件不计 uptime、事件级订阅、组件展示控制、订阅者批量导入导出,这些细节差异和价格测算已经放在 状态页对比文档 里,这里不重复贴表。
为什么不自己搭一个
工程师看到状态页,第一反应很容易是「这我自己也能写」。如果只是画几个组件、写几条事件时间线,确实不难。但状态页麻烦的地方不在页面。
先是信任。状态页是给外部看的,放在一个独立于你的第三方平台上,比放在你自己的服务器上更可信。你出问题的时候,别人不用怀疑你在自说自话,也不用担心状态页和业务系统一起挂掉。这一点,自建从结构上就给不了。
然后是长期维护。状态页不是静态页。订阅管理、邮件送达、可用性统计、事件时间线、内部页,都得有人写,也得有人长期维护。对绝大多数团队来说,这不是核心业务,投进去的工程时间很难回本。
还有一些东西短期补不齐。最典型的是邮件声誉:给上万订阅者可靠送达,靠的是长期攒下来的 IP 与域名信誉、SPF/DKIM/DMARC、退信和投诉处理。攒不够,就进垃圾箱。故障时的流量洪峰也一样,状态页平时冷清,一出事所有人同时涌进来,峰值常比业务还猛。这两件事不是多写几行代码能解决的,是时间和规模的函数。
迁移会不会惊动订阅者
DeepSeek 这次是迁移,不是重搭。
Flashduty CLI 把风险拆成两步。先跑 flashduty statuspage migrate structure,把组件、分组、历史事件、通知模板导进来,不碰订阅者;在控制台核对结构和历史没问题,再跑 flashduty statuspage migrate email-subscribers 导订阅者。订阅者导进来直接是活跃态,不用重新验证邮箱。最后把自定义域名 CNAME 指过去,确认无误上线。
RSS 订阅者也不用动:Flashduty 兼容 Atlassian 的 history.rss / history.atom 格式,老地址照常拉。命令参数和完整步骤在 状态页对比文档 的迁移一节。
这次迁移说明了什么
状态页选型不能只看“能不能展示服务状态”。DeepSeek 这次迁移说明,要算的是中文、采购成本、自建可信度、邮件声誉、故障流量和订阅迁移这些问题。
如果你也在 Atlassian Statuspage 上,用户又主要看中文,这条路可以直接抄。
相关文档: