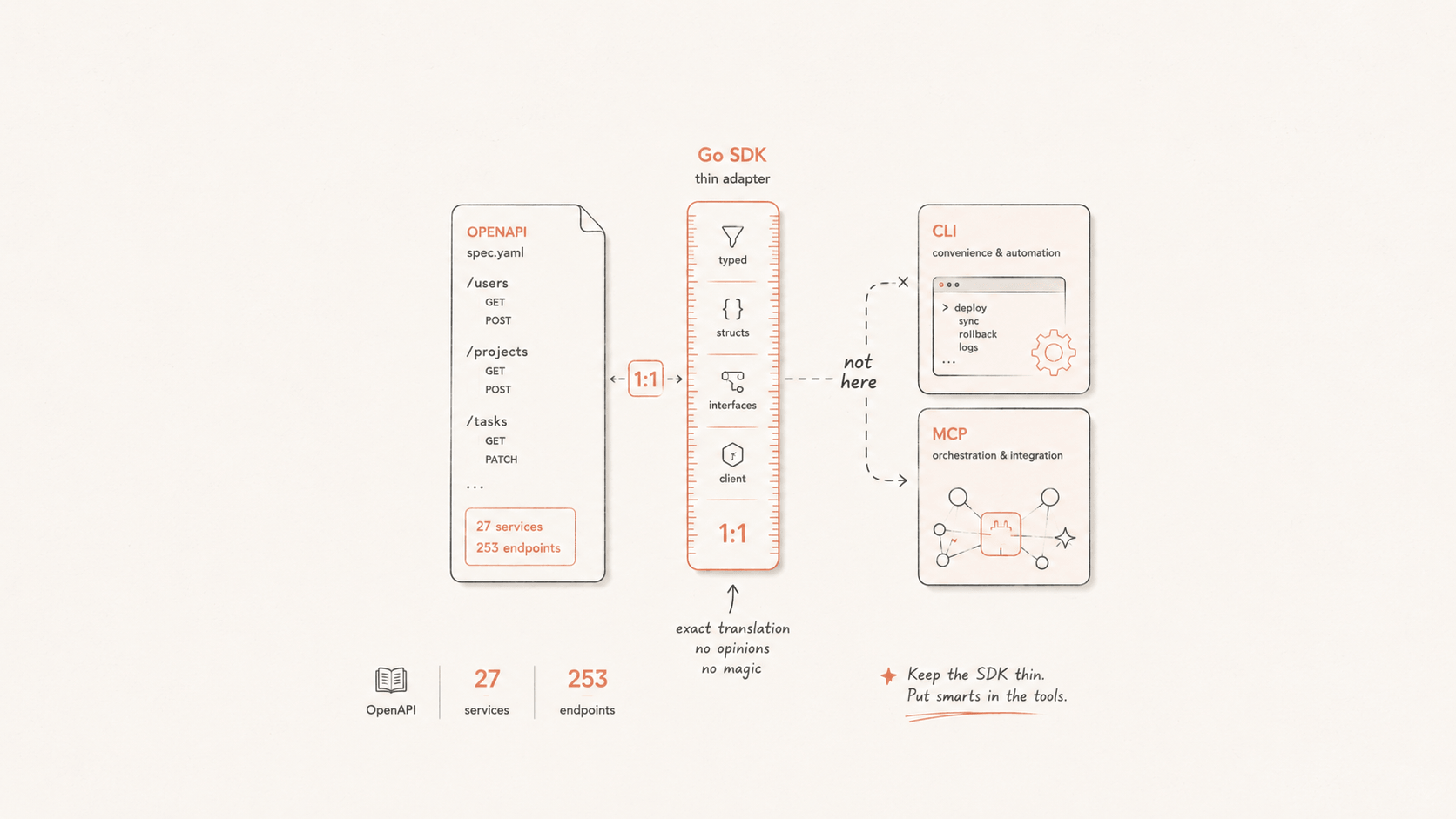
我们刚刚发布了 go-flashduty v0.5.3,Flashduty Open API 的官方 Go 客户端。它覆盖了 27 个服务下的全部 253 个 REST 接口,每个方法都有单元测试,并对线上真实 API 做过端到端校验。
但我们更想聊的不是「我们做了一个 SDK」。这里有个绕不开的工程问题:当一个 API 有 253 个接口、还在持续演进时,它的官方 SDK 应该长什么样、又该如何维护,才能不在两年后变成一团没人敢动的代码?
这篇文章讲我们在三个关键决策上的取舍:用代码生成而不是手写、把 SDK 钉死在与 API 严格 1:1 的边界上、以及如何保证 SDK 永远不和 OpenAPI 规范漂移。
253 个接口,先排除「手写」这条路
直觉上,手写一个 SDK 似乎更「精致」,每个方法可以单独打磨命名、加点贴心的便利逻辑。但当接口数量上到三位数、并且后端还在持续迭代时,手写会立刻暴露两个致命问题。
第一是一致性会失控。253 个方法如果靠人一个个敲,分页参数叫 Limit 还是 PageSize、错误怎么包装、时间字段怎么处理、响应里 request_id 放在哪,这些决定会随着写代码的人和时间慢慢分叉。三个月后你会有三种分页写法、两种错误类型,谁都说不清哪种是「对的」。
第二是会持续腐化。后端每加一个接口、改一个字段,就要有人记得回来同步 SDK。现实是没人会记得,于是 SDK 永远落后于 API 半个版本,文档和代码对不上,用户提 issue 你才发现漏了。
所以我们从一开始就决定:SDK 由 OpenAPI 规范代码生成。 接口分组、方法签名、请求/响应类型,全部从那份单一规范派生出来。一致性不再靠人的纪律来维持,而是由生成器保证,所有方法天然长一个样:
client, err := flashduty.NewClient("YOUR_APP_KEY")
if err != nil {
log.Fatal(err)
}
list, resp, err := client.Incidents.List(context.Background(), &flashduty.ListIncidentsRequest{
Progress: "Triggered",
ListOptions: flashduty.ListOptions{Limit: 20},
})
if err != nil {
log.Fatal(err)
}
fmt.Printf("request_id=%s total=%d has_next=%t\n", resp.RequestID, resp.Total, resp.HasNextPage)
for _, inc := range list.Items {
fmt.Printf("[%s] %s\n", inc.IncidentSeverity, inc.Title)
}client.Incidents、client.Alerts……每个服务一组方法,每个方法都返回统一的 (*T, *Response, error)。你学会用一个接口,就等于学会了全部 253 个。这种「无聊的一致性」正是大型 SDK 最值钱的属性。
「薄」是一种纪律:SDK 与 API 严格 1:1
Codegen 解决了「怎么把接口搬进来」,但还有一个更难、也更容易跑偏的问题:这些方法里到底该放多少逻辑?
我们的答案非常克制。每个方法精确对应一次 HTTP 调用,不多不少。 没有跨接口的隐式拼装,没有「贴心」的二次封装。这条边界听起来像是偷懒,但它是我们守得最严的一条规矩。
举个会反复遇到的诱惑。Flashduty 里很多资源既能用完整 ID 访问,也能用更短、对人更友好的短 ID。一个「为用户着想」的 SDK 似乎应该:你传个短 ID 进来,我帮你先调一次解析接口拿到完整 ID,再去调你想要的那个接口。看起来很贴心。
但我们坚决不在 SDK 里做这件事。原因是:
它会破坏可预期性。 SDK 用户调用 Incidents.Info,理应只发出一次 HTTP 请求。一旦我们偷偷在背后多发一次解析请求,调用次数、延迟、限流计数、出错时的归因,全都对不上用户的心智模型了。他在监控里看到两倍的请求量,会一脸困惑地来问为什么。
它会让 SDK 慢慢腐化。 短 ID 解析只是第一个口子。开了这个口子,下一个就是「列表接口能不能自动翻页」「能不能帮我把关联资源一起拉回来」。每一个单独看都「挺合理」,叠加起来 SDK 就变成了一个语义模糊、行为不可预测、谁都不敢删的胖客户端。
所以我们立了一条明确的分层规矩:SDK 严格与 API 1:1;所有消费侧的便利逻辑(短 ID 解析、自动翻页、跨资源拼装)一律放在上层的 CLI 和 MCP 里,绝不下沉进 SDK。 我们也绝不会为了「贴心」去不合理地复用某个接口、让它干本不该它干的事。
这条边界带来的好处是复利式的:SDK 这一层永远薄、永远可预测、永远好测,因为它要做的事情少且确定。复杂多变的便利逻辑活在更上层,那里本来就更适合迭代和试错,改坏了也不会污染底座。
薄,不等于简陋
需要澄清的是,「薄」指的是不替你做业务决策,而不是把粗糙的 HTTP 细节甩给你。在「让一次 API 调用用起来顺手」这件事上,SDK 该做的一点没省。
比如时间字段。API 在线上传的是 Unix 时间戳整数,直接暴露这种裸整数对人和日志都不友好。所以响应里的时间字段被处理成了 Timestamp 类型,默认按 RFC3339 字符串呈现,JSON、日志、乃至喂给大模型的输出都直接可读,而原始 epoch 仍然一个方法之遥:
inc := list.Items[0]
fmt.Println(inc.StartTime) // 2026-05-30T14:37:11+08:00
epoch := inc.StartTime.Unix() // 1779514631 (原始 wire 值)
t := inc.StartTime.Time() // time.Time比如错误处理。你不用去比对错误字符串,直接用类型化的判断,而且能穿透被包裹的错误(底层是 errors.As):
if flashduty.IsNotFound(err) { /* ... */ }
if flashduty.IsRateLimited(err) { /* ... */ }再比如重试。这里我们做了一个刻意的取舍:重试不内置进核心。它作为一个可选的 retry 子包存在,以 http.RoundTripper 中间件的形式组合进来。
client, err := flashduty.NewClient("YOUR_APP_KEY",
flashduty.WithTransport(retry.New(
retry.WithMaxRetries(3),
)),
)这同样是 1:1 哲学的体现:核心客户端只负责「发一次请求」这件确定的事;重试、缓存、链路追踪这些横切关注点,统统作为 transport 中间件可插拔地组合上去,而不是焊死在核心里。你想要就装上,不想要它就不存在。
不漂移:让规范成为唯一真相
最后是维护问题,也是最容易被忽视的一环。一个 SDK 发布那天通常是对的,难的是一年后它还对不对。
我们的防漂移策略只有一句话:OpenAPI 规范是唯一真相源,代码从它生成,而不是反过来。 后端接口怎么变,先改在规范里,SDK 跟着重新生成。人不需要手动同步 253 个方法,因为根本没有「手动同步」这个环节。
在此之上压两道校验。每个方法都有单元测试守住生成结果的形状;整套 SDK 还对线上真实 API 做过端到端校验,确认生成出来的请求/响应真的和服务端对得上。codegen 保证「内部自洽」,e2e 保证「和现实一致」,两者缺一,SDK 都会在某个时刻悄悄说谎。
最后守住的是这条线
这三个决策最终都落在同一条原则上:让 SDK 只做一件确定的事,并把它做到可预测。 Codegen 保证它从规范长出来、不靠人维持一致;1:1 边界保证它不长出语义不明的便利逻辑;规范作为唯一真相保证它不和现实漂移。薄,不是因为我们偷懒,而是因为薄才扛得住时间。
如果你在用 Go 接 Flashduty(写自动化、做集成,或是给 AI Agent 配一套可靠的工具),go-flashduty 已经在 GitHub 上,go get 即可开始。