For many teams, alert management starts with a group chat bot.
It is fast, cheap, and easy to wire up. In a few minutes, alerts from Prometheus, Zabbix, Nightingale, cloud monitoring, or an internal script can land in WeCom, Feishu, DingTalk, Slack, or another chat room. The screen finally moves. Phones start buzzing at night. For a team that is just getting monitoring under control, this step has real value: alerts no longer sit unseen in a console nobody opens.
Then the next problem appears. When enough messages arrive, everyone has "seen" the alert, but nobody knows whether they are supposed to act. The on-call engineer assumes the service owner is looking. The service owner assumes the operations team is already investigating. The operations team assumes it is an application issue. Ten minutes later, someone asks, "Who is handling this?" and the room starts backfilling ownership, screenshots, and context.
That is not a notification failure. The notification worked.
The failure is response.

Group Chat Creates Visibility, Not Accountability
The strongest thing about an IM bot is that it moves alerts from a monitoring console into the place where the team already works. It lowers the integration cost and makes information more transparent. But it does not answer the questions that matter most: Who is on call right now? Who owns this alert? Has anyone acknowledged it? When should it escalate? Who closes it? Will there be a postmortem? Can the same class of issue alert less often next time?
If those questions are unanswered, a busier room just creates a messier incident.
Google SRE's monitoring guidance is clear on why alerts interrupt people: something is wrong, and a human needs to investigate, mitigate, and understand the cause. Low-quality, frequent alerts teach people to skim or ignore pages that might actually matter. IBM's definition of alert fatigue points to the same failure mode: too many low-priority, false, or unactionable notifications create mental and operational fatigue, which slows response.
The first test of alert governance is not "Was the alert sent?" It is "Can this alert make a specific person take action?" In other words, the alert must be actionable and must have an owner. If a P1 incident and a low-value reminder look almost the same in a chat room, and people judge urgency by feel, the system is not responding. It is broadcasting.
The Response Chain Is Longer Than a Chat Message
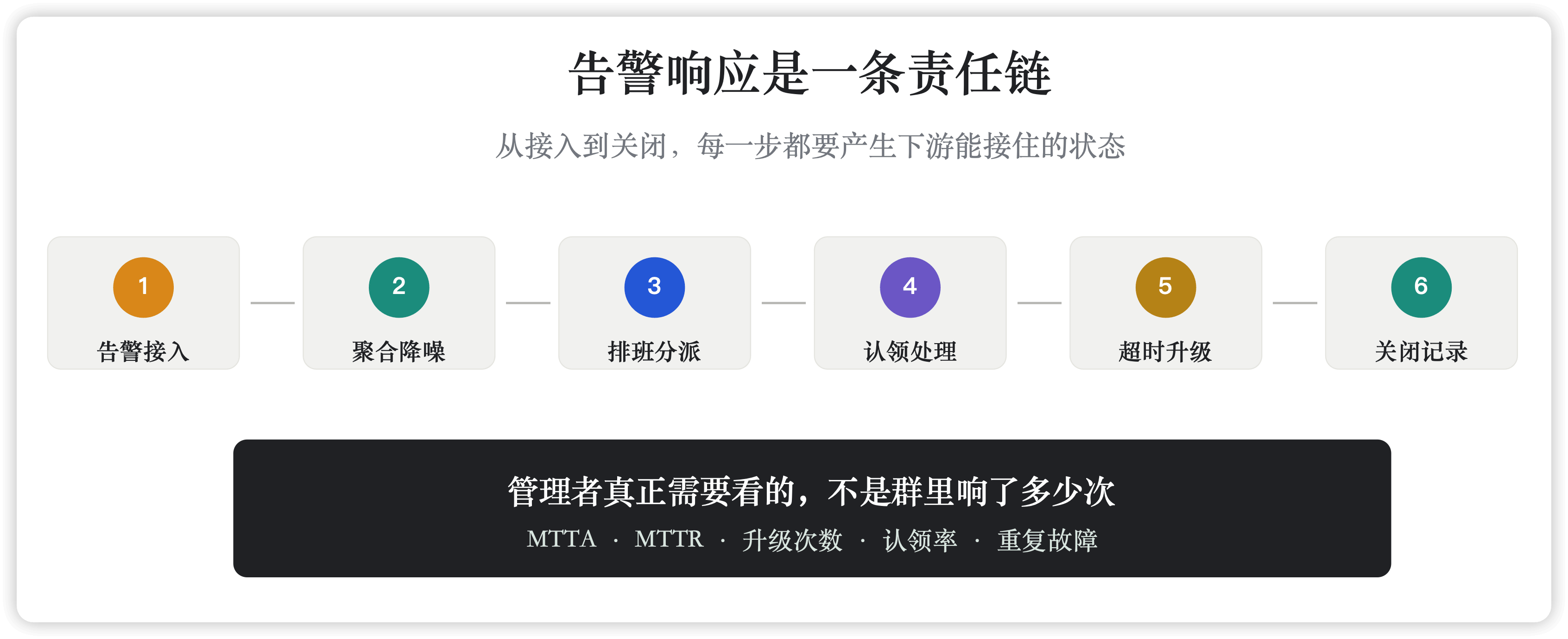
After a critical alert reaches the team, several things should happen.
First comes noise reduction. Duplicate alerts, derived alerts, and multiple signals caused by the same failure should not all scroll through the room as equal messages. Otherwise the responder's first job is not troubleshooting. It is finding the main thread in the noise.
Then dispatch. The alert should enter the right service, team, or collaboration space, not default into one large room. Large rooms are useful for progress updates. They are a poor place to assign primary responsibility.
Then reachability and schedules. A critical alert has to find the person who should respond right now. That person may be working, asleep, or on holiday. The channel may be chat, phone, SMS, email, or app push. If nobody acknowledges within a defined window, the system should escalate to the secondary responder, the lead, or another team.
Then acknowledgment, handling, and closure. Acknowledgment is not someone typing "I'll take a look." It is a state recorded in the response system. Closure is not someone saying "fixed" in the room. It should be possible to open the alert record later and see who handled it, when they handled it, and why it was closed.
Finally, review and governance. Atlassian's incident postmortem guidance emphasizes consistent questions, enough data, timelines, chat records, tickets, and follow-up actions. These are hard to reconstruct from memory after the fact. They should fall out of the response process as it happens.
Leaders Need to Know Whether the Process Is Improving
Operations leaders, SRE leaders, and platform leaders should not measure alerting by asking, "How many times did the room buzz today?" That only tells you the monitoring system is busy. It does not tell you whether the organization responds better.
The more useful questions are: How long did critical alerts take to acknowledge? Which teams often exceeded the acknowledgment window? Which services repeatedly triggered the same alert? Which alerts were closed as invalid? Which incidents escalated, and why? After the review, did thresholds change, runbooks improve, configuration change, or architecture work begin?
Those questions map to MTTA, MTTR, escalation paths, repeated incidents, invalid-alert rates, and postmortem action completion. They are imperfect, but they move the conversation from "Did everyone see it?" to "Is the organization becoming faster, steadier, and more traceable?"
A chat bot alone cannot answer those questions. Chat is good for discussion. It is bad at preserving structured state. Messages get buried under reactions, side conversations, screenshots, and forwarded notes. Schedules live somewhere else. Escalation rules are remembered by people. Closure is shared verbally. When leadership asks where last week's incident got stuck, the team ends up searching chat history.
This is why many teams eventually move from group chat alerts to an On-call system. Not because chat is useless, but because chat is a collaboration surface, not a system of responsibility.
On-call Turns "Seen" Into "Owned"
A mature alert response system usually connects ingestion, noise reduction, routing, schedules, escalation, reachability, acknowledgment, closure, and analytics. Flashduty's On-call model is built around those same actions: multi-source integrations, alert grouping and suppression, flexible dispatch, multi-channel notifications, on-call schedules, escalation paths, and responder acknowledgment, handling, and closure.
This is not replacing a chat bot with a more complicated notification tool. The object of responsibility changes.
Before, one message entered a room and everyone "saw" it together. Now, an event enters a response workflow, is dispatched to the owning team and on-call responder, escalates if nobody responds, closes with state if it is resolved, and leaves data for later analysis if it repeats. IM still matters. It carries communication, progress updates, and war-room collaboration. It is just no longer the only source of truth.
For CIOs and platform leaders, that difference matters. You cannot explain a core business outage with "someone in the room should have seen it." You also cannot prove reliability governance is improving by saying "we were active in chat." You need a process that is auditable, traceable, and reviewable.
Of course, tools do not carry organizational responsibility for you. An On-call platform cannot define service boundaries, team ownership, or alert quality on its own. If ownership is unclear, alert rules are configured casually, and escalation paths are not maintained, any system can become another message relay. What the tool can do is expose those organizational gaps so they no longer hide inside scrolling chat history.
Start With the Last 10 Critical Alerts
You do not need a major program to begin. Take the last 10 critical alerts and ask the same questions for each one:
- Was there a clear owner?
- Was there an acknowledgment time?
- Was there an escalation path?
- Was there a closure record?
- Was there a postmortem conclusion or follow-up action?
If most answers require searching chat, asking people, or guessing context, you have alert notification, not incident response.
Sending alerts to a group chat is a starting point, not the finish line. The system worth building is one where every critical alert finds an owner, drives action, leaves a record, and makes the next response a little faster.
If this is the direction you want to build toward, take a look at Flashduty.