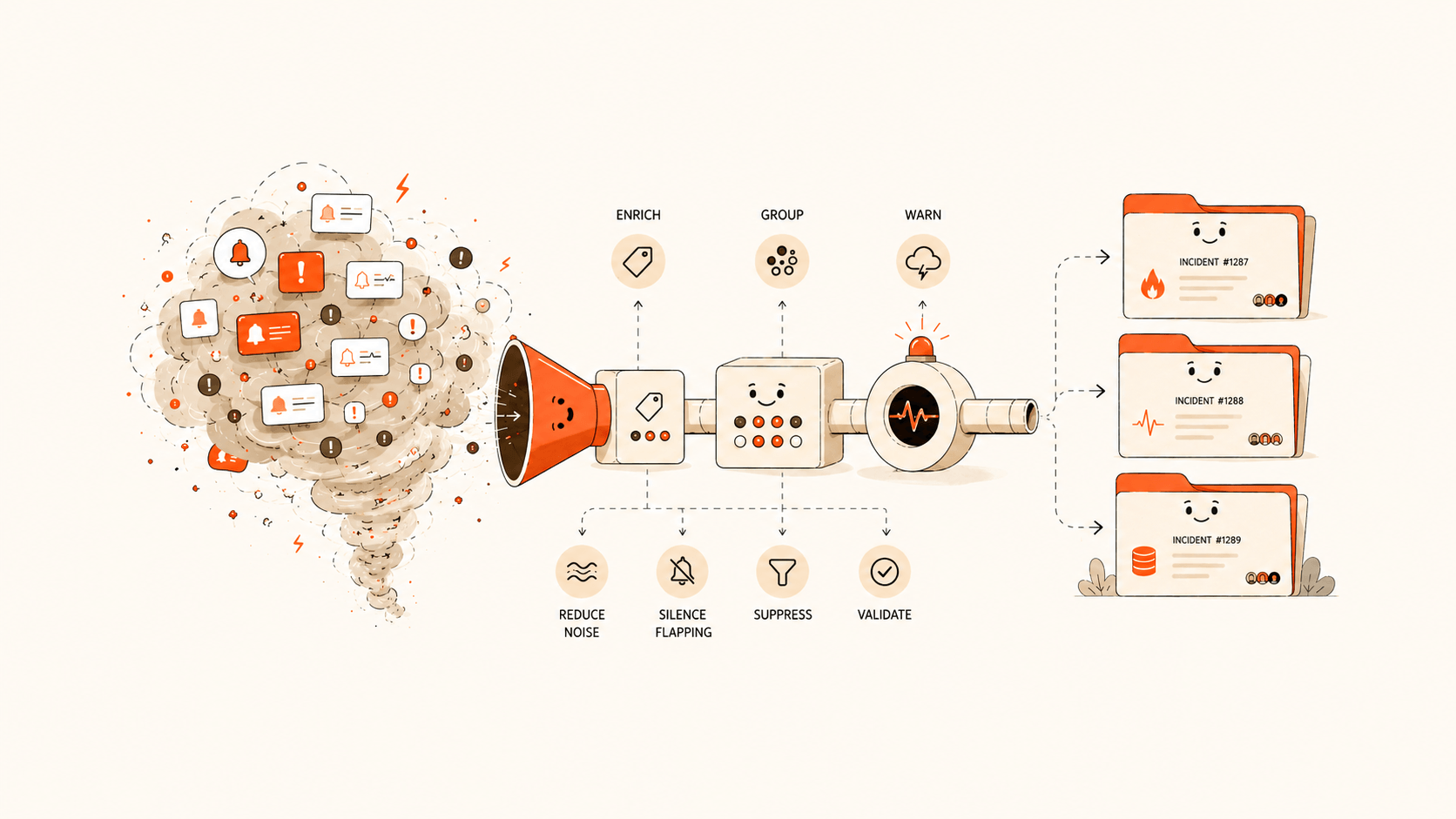
An alert storm is not just "too many notifications."
Too many notifications are only the symptom. The deeper problem is that monitoring systems push many events to humans, while the response system does not organize those events into incidents that can be understood, dispatched, acknowledged, and escalated.
If one server outage triggers 100 alerts, the on-call engineer should not handle 100 separate tasks.
If one network flap repeatedly triggers and recovers, the responder should not be bombarded continuously.
If one data-center network issue fans out into many host, service, and database alerts, the team should not rely on group chat to guess the root cause.
The goal of alert noise reduction is not to make alerts disappear. It is to converge many alerts into a small number of actionable incidents.
Flashduty's noise-reduction model is built around this goal: events enter the system and become alerts, similar alerts are grouped into incidents, and later alerts join existing incidents without retriggering notifications. Combined with silences, suppression, flapping detection, storm warnings, Pipelines, and analytics, alert governance moves from "turn off rules by feeling" to a measurable response process.
First Correction: Noise Reduction Is Not Deleting Alerts
Many teams hear "noise reduction" and immediately go to the monitoring system to delete rules, raise thresholds, or turn off low-severity alerts.
Sometimes that is necessary, but it should not be the first step.
Deleting rules has risk. Delete too much and you may lose early signals. Raise thresholds too aggressively and alerts may fire only after users are affected. Turn off all Warning alerts and the short-term silence may cost you capacity, performance, and dependency warnings.
A safer approach is layered:
- Source cleanup: discard or rewrite events that have no response value.
- Label completion: give alerts stable dimensions for routing, grouping, and analytics.
- Alert grouping: merge similar alerts into one incident.
- Silencing and suppression: handle maintenance windows, known issues, and derived alerts.
- Flapping detection and delay windows: reduce interruptions from short-lived recoveries and repeated triggers.
- Data review: use incident count, interruption count, MTTA, MTTR, and alert top lists to decide what to fix next.
The advantage is that you do not need to change all monitoring rules on day one. First catch, converge, dispatch, and measure alerts in the response layer; then go back to the monitoring layer to improve rules that truly need improvement.
Understand Three Objects: Event, Alert, Incident
Before reducing noise, define the objects.
Flashduty's model can be simplified as:
Monitoring system → Event → Alert → IncidentAn event is the raw notification from a monitoring system. A trigger, recovery, or update can all be events.
An alert is created from events. Multiple events for the same alert, such as trigger, update, and recovery, enter the same alert.
An incident is the handling object. Similar alerts can be grouped into one incident, and that incident is dispatched, notified, acknowledged, escalated, and closed.
This model is essential.
Without noise reduction, one alert often becomes one incident, and responders see many independent incidents. With noise reduction, many similar alerts can enter the same incident, so the responder handles one problem instead of many notifications.
Step 1: Establish a Baseline Before Changing Rules
Before changing anything, look at real alert data.
Answer these questions:
- How many incidents occurred in the last week?
- What are the proportions of Critical, Warning, and Info?
- Which alert checks and alert objects are most frequent?
- Which notifications happen during sleep time?
- Which alerts are never acknowledged?
- Which incidents contain many alerts or events?
- Which services often trigger and then recover quickly?
Flashduty analytics can show incident data by team, workspace, individual, and other dimensions. Metrics include incident count, MTTA, MTTR, response rate, response effort, and interruption count. Time can be split into work, rest, and sleep periods. Global views show the top 20 alert checks and alert objects.
Do not rush toward a single "compression rate" number.
Record four baselines first:
Raw alert volume: how many events and alerts monitoring systems pushed
Incident count: how many actionable incidents Flashduty created
Notification interruption: how many interruptions SMS, phone, and App push caused
Response efficiency: whether MTTA, MTTR, and response rate are healthyAfter each policy change, revisit these four numbers. Otherwise, it is easy to mistake "fewer notifications" for "better reliability."
Step 2: Complete Labels So Alerts Can Be Governed
Noise reduction depends on labels.
If an alert only has a title and description, routing, grouping, silencing, and suppression are difficult to maintain. Teams need at least several stable labels:
service: business service or application.resource: alerting object, such as host, instance, Pod, or database.check: alert check, such as CPU, disk, or API error rate.env: environment, such as production or staging.team: owning team.clusterorregion: cluster, data center, or region.
Flashduty label enrichment can automatically generate or modify labels when alerts enter the system. It can extract values from title, description, or existing labels with regex; combine fields into new labels; map IDs into readable values; or delete labels that are not needed. Advanced scenarios can use API mapping to query external systems and add team, service tier, and other metadata.
Label enrichment is not cosmetic. It directly affects governance quality.
The same resource can group alerts for the same object.
The same service can route alerts to the right workspace.
The same check can appear in alert-check top lists.
The same team can determine dispatch policy and ownership.
If labels are unstable, noise-reduction rules will be hard to maintain. Standardizing upstream alert fields is better than writing ten fragile regex rules.
Step 3: Clean Obvious No-Value Alerts at the Integration Layer
Some events should not enter the response workflow.
Examples include frequent development-environment restarts, known harmless errors, expected exceptions from load tests, and low-value state changes that nobody will handle. If these events enter workspaces, they consume storage, routing, grouping, and analytics capacity, and they distort governance decisions.
Flashduty's alert processing Pipeline runs at the integration layer after label enrichment and before routing. It can clean, transform, and filter alerts.
Common uses include:
- Custom severity: for example, upgrade Warning alerts from the payment service to Critical so they trigger stronger notification.
- Title or description rewrite: turn machine-generated titles into readable business language, or append Runbook and Dashboard links.
- Alert discard: drop clearly valueless events before storage.
- Integration-layer suppression: handle global dependency relationships within the same integration.
One boundary matters: recovery events with event_status=Ok do not pass through the alert processing Pipeline. They directly enter the alert merge flow. Do not design a workflow that assumes recovery events will be discarded, rewritten, or suppressed by Pipeline.
Pipeline rules affect all alerts from that integration no matter which workspace they route to. Put only globally agreed rules at the integration layer. Policies that affect one team belong at the workspace layer.
Step 4: Group Many Alerts Into One Incident
Grouping is the core action for alert storms.
Grouping does not hide alerts. It merges similar alerts into one incident, so the responder handles one incident while still being able to inspect related alerts and raw events inside incident details.
Flashduty supports two grouping modes.
Intelligent grouping is good for fast adoption. It calculates similarity from title, description, labels.service, labels.resource, and other fields. By default, fields such as title, description, labels.service, and labels.resource participate in matching; teams can customize fields up to a maximum of 10.
Rule-based grouping is good when boundaries need to be explicit. It matches specified attributes or labels exactly. Rule-based grouping supports unified control and fine-grained control: different alert types can match different conditions and use different grouping dimensions. A single rule has backend limits on grouping dimensions, with no more than 5 dimensions per group and no more than 100 fine-grained branches.
A practical starting point:
Infrastructure alerts: group by labels.resource + labels.check
Application alerts: group by labels.service + labels.check + labels.env
Kubernetes alerts: group by labels.cluster + labels.namespace + labels.workload
Database alerts: group by labels.service + labels.resource + labels.checkIf labels are incomplete, use intelligent grouping first to reduce noise quickly. If incorrect grouping is risky, switch to rule-based grouping for precise control.
Set grouping windows carefully. Without a grouping window, new alerts keep entering an existing incident until it closes. With a grouping window, alerts join during the window, and alerts after the window create a new incident. The window can start when the incident triggers or when an alert joins the incident; the latter recalculates the window each time a new alert joins and is useful for ongoing storm scenarios.
Step 5: Use Storm Warnings When Grouped Incidents Are Still Serious
Grouping reduces repeated notifications, but a grouped incident may still be severe.
In fact, an incident that keeps absorbing alerts often means the blast radius is growing. The team may need stronger response, not less attention.
Flashduty storm warnings handle this case. When the number of grouped alerts reaches a threshold, the system records an alert-storm event in the incident timeline and sends a storm-warning notification. Up to 5 thresholds can be configured, each from 2 to 10,000.
Treat storm warnings as a secondary escalation signal.
For example:
- At 20 grouped alerts, remind the current responder to confirm impact.
- At 100 grouped alerts, escalate to the team lead.
- At 500 grouped alerts, enter major-incident response.
Do not copy thresholds blindly. Infrastructure, application, Kubernetes, and cloud-service alerts have different densities. Use historical data: inspect the number of related alerts in similar incidents from the past two weeks, then set thresholds that are neither too sensitive nor too late.
Step 6: Use Flapping Detection for Repeated Trigger and Recovery
Not every alert storm comes from a continuing incident. Some come from flapping.
Short network blips, occasional dependency timeouts, near-threshold node pressure, and unstable monitoring collection can all make the same incident trigger and recover repeatedly. For responders, this is exhausting because every trigger looks like a new problem.
Flashduty flapping detection marks an incident as flapping when it repeatedly changes between trigger and recovery. New workspaces enable flapping detection by default in "notify only" mode.
It has three key parameters:
- State-change count: default 4, range 2 to 100.
- Observation window: default 60 minutes, range 1 to 1440 minutes.
- Silence duration: default 120 minutes, range 30 to 1440 minutes, only active in "notify then silence" mode.
Start conservatively.
Use "notify only" first and observe which alerts are marked as flapping. After confirming that they are truly short-lived fluctuations, enable "notify then silence" for specific alert types. Do not silence all flapping from the beginning, or you may hide a real incident that is repeatedly deteriorating.
Delay windows in dispatch policies can also help. A delay window waits before sending the first notification, with a range from 0 to 3600 seconds. If the incident closes during the delay, no notification is sent. For self-healing network timeouts and transient flaps, this is more reasonable than immediate phone calls.
Step 7: Use Silences for Maintenance Windows and Known Issues
Silences are for alerts that are known and temporarily do not need notification.
Typical scenarios include planned maintenance, bulk releases, load tests, data migrations, hardware replacement, scheduled restarts, and known-issue repair windows. The alert itself is expected, so continuing to notify only creates noise.
Flashduty silence rules support one-time silences, recurring silences, and service-calendar-based silences. Conditions can match severity, title, description, integration source, and labels, with AND/OR logic. Behavior can either discard directly or keep and mark. When kept and marked, alerts still appear in the raw alert list and are marked as silenced for later filtering.
Prefer "keep and mark."
Direct discard is quiet but removes useful troubleshooting context. Keeping the mark shows what the silence matched and helps reviews determine whether the silence scope was too broad.
Flashduty also supports quick silence. A responder can create a temporary silence from incident details through "More actions → Quick silence." It defaults to 1 day and is automatically removed after expiration. Repeating quick silence on the same incident edits the original rule instead of creating duplicates.
Every silence needs an expiration. Do not turn temporary problems into permanent silences.
Step 8: Use Suppression for Root Cause and Derived Alerts
Suppression is for dependency relationships.
For example, if a data-center network fails, downstream hosts, databases, applications, and APIs may all alert. The priority is the data-center network failure; the other alerts are derived symptoms. Sending all derived alerts to humans makes the root cause harder to see.
Flashduty suppression policies automatically suppress related secondary alerts when a root-cause alert exists. A common example is suppressing Warning/Info incidents for the same check when a Critical incident exists.
Suppression conditions have three parts:
- New alert condition: which alerts should be suppressed, such as Warning/Info.
- Active alert condition: which alerts act as the suppression source, such as Critical.
- Same fields: attributes or labels that must match, such as check item or hostname.
Suppression requires a matching active alert within 10 minutes. Active alerts are alerts that have not been acknowledged and have not recovered.
Suppression can be configured in a workspace or at the integration layer. Pipeline suppression at the integration layer only matches active alerts within the same integration, which is suitable for global suppression logic such as suppressing all alerts from a data center after a data-center network outage. Workspace suppression matches all active alerts in the same workspace and is suitable for team-specific dependencies.
Suppression is not simply hiding all lower-severity alerts. It must clearly express which alert is the source, which alert is the target, and which dimensions must be the same. That is safer than silencing all Warning alerts.
Step 9: Understand Exclusion Rules and Discard Risk
Some events can be excluded or discarded directly, but this should be the last resort.
Workspace exclusion rules discard events as they enter, creating no alert or incident records. Pipeline discard also drops data before storage. Both are suitable only for events that have no value and require no audit trail.
Silence and suppression are different. They still match and process alerts at the alert layer. Matched alerts do not trigger notification, but if you keep marks, you can still inspect them later.
A safe rule priority is:
- Use exclusion or Pipeline discard for events that are clearly valueless and need no audit.
- Use silences for maintenance windows and known issues.
- Use suppression for derived alerts when a root cause exists.
- Use grouping for bursts of similar alerts.
- Use flapping detection and delay windows for repeated trigger/recovery.
Do not chase quietness by discarding large volumes of alerts. Quiet is not the same as reliable.
Step 10: Validate Noise Reduction Over 14 Days
Alert noise reduction should not be a one-time "big rule change."
A better approach is a 14-day experiment. Choose one noisy workspace and validate in stages.
Days 1-2: ingest real alerts and avoid changing rules immediately. Observe incident count, alert top lists, sleep-time interruption count, MTTA, MTTR, and response rate.
Days 3-5: complete labels. Ensure at least service, resource, check, env, and team are available. Use label enrichment for extraction, combination, or mapping when needed.
Days 6-8: enable grouping. Start with the noisiest 5 to 10 alert types. Use intelligent grouping for a quick trial, or rule-based grouping when dimensions are clear.
Days 9-10: configure silences and flapping detection. Move maintenance windows, known issues, and short-lived self-healing alerts out of strong notification paths.
Days 11-12: configure suppression and storm warnings. Handle root-cause and derived-alert relationships, and add secondary reminders for incidents that absorb large numbers of alerts.
Days 13-14: review data. Compare:
- Did incident count decrease?
- Did interruption count decrease, especially during sleep time?
- Did Critical MTTA stay stable or improve?
- Did Warning/Info alerts decrease in strong notification channels?
- Are the top 20 alert checks concentrated in a few rules?
- Is it easier for responders to identify the incidents that matter now?
If notifications decreased but Critical MTTA became longer, the strategy is too aggressive.
If incident count dropped but top alert checks remain concentrated, go back to the monitoring system and tune rules.
If interruptions fell while MTTA/MTTR did not worsen and responders can identify issues faster, the strategy is producing value.
A Reusable Noise-Reduction Template
Start with this minimal template:
Label enrichment:
- Extract service, resource, check, env, team
- Use mapping tables to complete team or service_name
Pipeline:
- Discard no-value alerts from dev/test environments
- Rewrite titles while preserving service, resource, check, and env
- Upgrade specific Warning alerts from core services to Critical
Grouping:
- Infrastructure: resource + check
- Application service: service + check + env
- Database: service + resource + check
Flapping detection:
- Start with notify-only mode
- Enable notify-then-silence for confirmed self-healing short flaps
Silence:
- Use one-time silence for maintenance windows
- Use recurring silence for scheduled tasks
- Prefer keep-and-mark instead of no-record discard
Suppression:
- When Critical exists, suppress Warning/Info under the same service/resource/check
- Handle data-center or cluster-level failures at the integration layer
Storm warning:
- Configure 2 to 3 thresholds for high-frequency incidents
- Enter escalation or major-incident flow when thresholds are reached
Validation:
- Weekly review incident count, interruption count, MTTA, MTTR, response rate, and alert top listsThis is only a starting point. Every team has different monitoring sources, label quality, service boundaries, and on-call practices. Effective noise reduction must come from real alert data.
Prove the storm is actually smaller
Alert storms cannot be solved by asking people to look at fewer messages.
Flashduty does not replace monitoring systems. It builds a response layer after Prometheus, Zabbix, Nightingale, Grafana, cloud monitoring, and internal systems: monitoring systems detect anomalies; Flashduty turns anomalies into actionable incidents and reduces unnecessary interruptions.
If your team is suffering from alert storms, start a 14-day experiment in one real workspace: ingest alerts, complete labels, enable grouping, configure silences and suppression, and add storm warnings. Judge the result using incident count, interruption count, MTTA, MTTR, and alert top lists. Fewer notifications only count as progress if Critical MTTA does not get worse and responders can find the real incident faster.
Request an Alert Noise-Reduction Assessment
References
- Flashduty product documentation: alert noise reduction, alert processing Pipeline, label enrichment, filter conditions, alert management, workspace configuration, dispatch policies, and analytics.