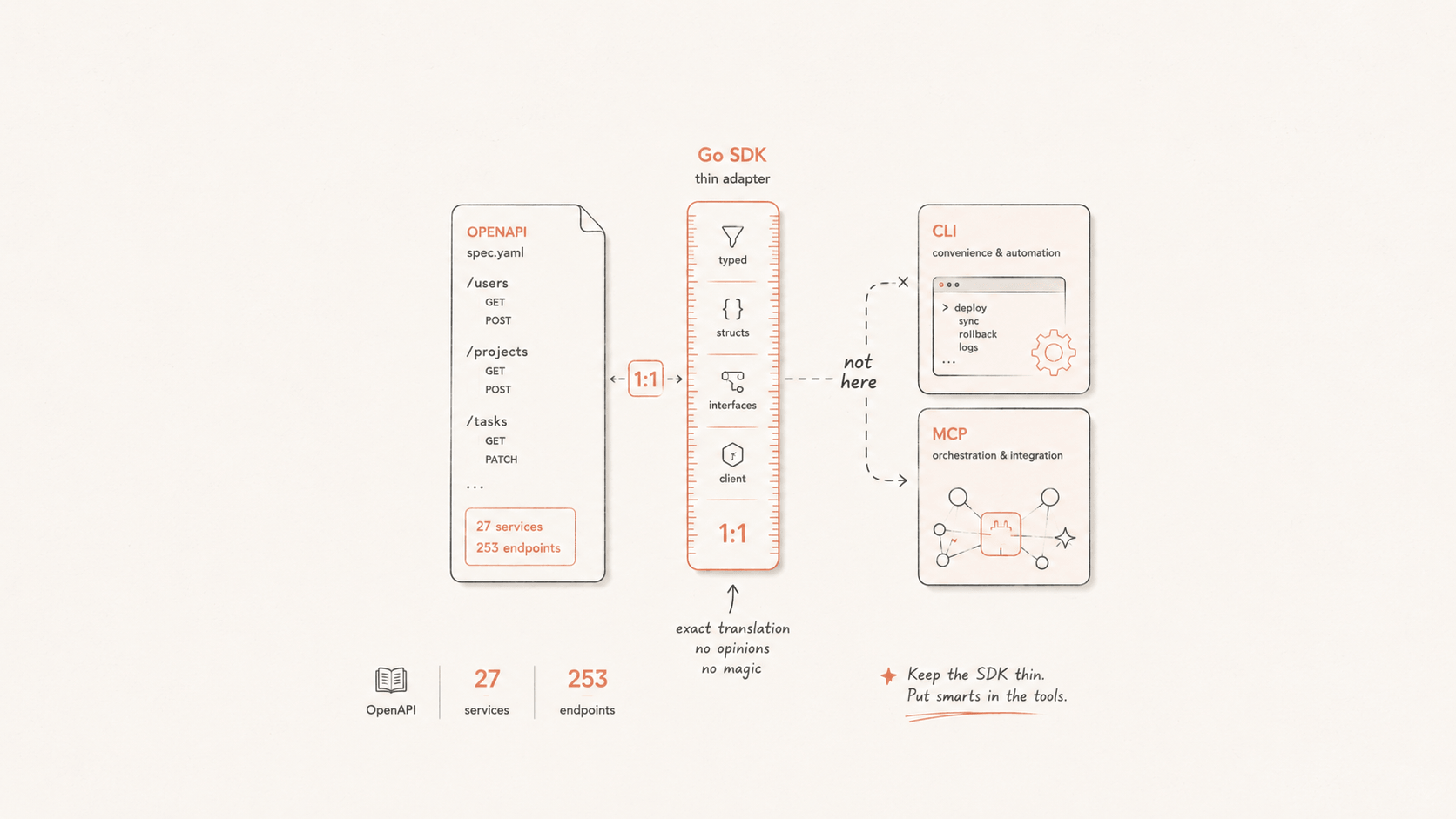
We just shipped go-flashduty v0.5.3, the official Go client for the Flashduty Open API. It covers all 253 REST endpoints across 27 services, every method is unit-tested, and the whole thing has been validated end-to-end against the live API.
But "we built an SDK" isn't what we want to talk about. The interesting part is a question you can't dodge once an API gets large enough: when an API has 253 endpoints and is still evolving, what should its official SDK look like, and how do you maintain it so it doesn't turn into a pile of code nobody dares to touch two years later?
This post walks through the tradeoffs behind three decisions: generating the SDK instead of hand-writing it, pinning it to a strict 1:1 boundary with the API, and making sure it never drifts from the OpenAPI spec.
253 endpoints: rule out hand-writing first
Hand-writing an SDK feels more "crafted." You get to polish each method's naming and sprinkle in a little convenience logic. But once you're into three digits of endpoints, with a backend that keeps moving, hand-writing exposes two fatal problems immediately.
The first is consistency falls apart. If 253 methods are typed out one by one, every small decision drifts with the author and the calendar: is the pagination field Limit or PageSize, how are errors wrapped, how are time fields handled, where does request_id live in the response. Three months in you have three pagination styles and two error types, and nobody can say which one is "right."
The second is it rots continuously. Every endpoint the backend adds and every field it changes requires someone to remember to come back and sync the SDK. In reality nobody remembers. So the SDK is permanently half a version behind the API, the docs disagree with the code, and you only find the gap when a user files an issue.
So we decided from day one: the SDK is generated from the OpenAPI spec. Service grouping, method signatures, request and response types all derive from that single spec. Consistency is no longer a matter of human discipline. The generator enforces it, and every method comes out shaped the same way:
client, err := flashduty.NewClient("YOUR_APP_KEY")
if err != nil {
log.Fatal(err)
}
list, resp, err := client.Incidents.List(context.Background(), &flashduty.ListIncidentsRequest{
Progress: "Triggered",
ListOptions: flashduty.ListOptions{Limit: 20},
})
if err != nil {
log.Fatal(err)
}
fmt.Printf("request_id=%s total=%d has_next=%t\n", resp.RequestID, resp.Total, resp.HasNextPage)
for _, inc := range list.Items {
fmt.Printf("[%s] %s\n", inc.IncidentSeverity, inc.Title)
}client.Incidents, client.Alerts, and so on. One group of methods per service, each returning the same (*T, *Response, error). Learn one endpoint and you've learned all 253. That "boring consistency" is the single most valuable property a large SDK can have.
"Thin" is a discipline: a strict 1:1 with the API
Codegen solves "how do we get the endpoints in." But there's a harder question, and the one most likely to go sideways: how much logic belongs inside these methods?
Our answer is deliberately spare. Every method maps to exactly one HTTP call, no more, no less. No implicit cross-endpoint stitching, no "helpful" second-order wrappers. That boundary may sound like laziness; it's actually the rule we guard most strictly.
Here's a temptation you'll genuinely run into. Many Flashduty resources can be addressed by both a full ID and a shorter, more human-friendly short ID. A "thoughtful" SDK would seem to want this: you pass in a short ID, it quietly calls a resolve endpoint first to get the full ID, then calls the endpoint you actually wanted. Looks considerate.
We refuse to do this inside the SDK. Because:
It breaks predictability. When you call Incidents.Info, exactly one HTTP request should go out. The moment we secretly fire an extra resolve request behind your back, the call count, the latency, the rate-limit accounting, the error attribution stop matching your mental model. You see double the request volume in your dashboards and come asking, baffled, why.
It makes the SDK rot. Short-ID resolution is just the first crack. Open that crack and the next one is "can the list endpoint auto-paginate," then "can it pull related resources back for me too." Each one looks reasonable in isolation; stacked up, the SDK becomes a fat client with murky semantics and unpredictable behavior that nobody dares to delete.
So we drew a clear line: the SDK is strictly 1:1 with the API, and all consumer-side convenience (short-ID resolution, auto-pagination, cross-resource stitching) lives in the layers above it, in the CLI and the MCP, never inside the SDK. And we will never unsoundly reuse an endpoint to make it "helpfully" do work it was never meant to do.
The payoff compounds. The SDK layer stays thin, predictable, and easy to test forever, because what it has to do is small and fixed. The complex, fast-changing convenience logic lives one layer up, where iteration and experimentation belong anyway, and where breaking something won't contaminate the foundation.
Thin is not crude
To be clear: "thin" means we don't make business decisions for you, not that we dump raw HTTP details in your lap. When it comes to making a single API call pleasant to use, the SDK skips nothing it should do.
Take time fields. The API sends Unix timestamp integers on the wire, and exposing those bare integers is unfriendly to humans and logs alike. So response time fields are typed as Timestamp, rendering as RFC3339 strings by default (readable in JSON, in logs, even in output you feed to an LLM) while the raw epoch stays one method away:
inc := list.Items[0]
fmt.Println(inc.StartTime) // 2026-05-30T14:37:11+08:00
epoch := inc.StartTime.Unix() // 1779514631 (raw wire value)
t := inc.StartTime.Time() // time.TimeTake error handling. You don't compare error strings; you use typed predicates that see through wrapped errors (errors.As under the hood):
if flashduty.IsNotFound(err) { /* ... */ }
if flashduty.IsRateLimited(err) { /* ... */ }And take retries. Here we made a deliberate call: retries are not built into the core. They live as an optional retry subpackage, composed in as http.RoundTripper middleware.
client, err := flashduty.NewClient("YOUR_APP_KEY",
flashduty.WithTransport(retry.New(
retry.WithMaxRetries(3),
)),
)That's the 1:1 philosophy again. The core client does the one certain thing: send a single request. Cross-cutting concerns like retry, caching, and tracing all compose in as transport middleware, pluggable rather than welded into the core. Add them if you want them; otherwise they simply aren't there.
No drift: make the spec the single source of truth
Finally, maintenance, the part most easily overlooked. An SDK is usually correct on the day it ships; the hard part is whether it's still correct a year later.
Our anti-drift strategy is one sentence: the OpenAPI spec is the single source of truth; code is generated from it, not the other way around. When a backend endpoint changes, the spec changes first, and the SDK is regenerated to follow. Nobody manually syncs 253 methods, because there is no "manual sync" step to begin with.
On top of that sit two layers of validation. Every method has unit tests pinning the shape of the generated result, and the whole SDK is validated end-to-end against the live API to confirm the generated requests and responses actually line up with the server. Codegen guarantees internal consistency; e2e guarantees consistency with reality. Drop either one and the SDK will quietly start lying at some point.
The line we keep
The three decisions come back to one principle: let the SDK do one certain thing, and do it predictably forever. Codegen keeps it grown from the spec instead of held together by discipline; the 1:1 boundary keeps it from sprouting murky convenience logic; the spec-as-truth keeps it from drifting off reality. Thin was never about being lazy. Thin is what survives time.
If you're reaching Flashduty from Go (writing automation, building an integration, or wiring a reliable toolset for an AI agent), go-flashduty is on GitHub, and go get gets you started.

