Kubernetes is the open-source implementation of Google's internal container orchestrator, Borg. Prometheus is the open-source counterpart of Borgmon, its internal monitoring system. So what about Outalator, Google's internal on-call tool. Is there a comparable product?
It's a natural question, but it quietly misses the point. In Site Reliability Engineering, Google's SRE team spends nearly three full chapters on how they run on-call, and tooling is only a small slice of it. What actually determines on-call quality is how three things mesh: culture, mechanisms, and tools. Tooling is the easiest layer to copy, which is exactly why it matters least.
This post unpacks two battle-tested approaches, Google SRE's and Datadog's, to see where the best companies actually put the work, and what a team can genuinely take away.
A public, hard target: keep toil under 50%
Google SRE has a well-known principle: use software engineering to solve operations problems, and drive down toil. In practice, they translate it into a public, measurable goal. No SRE should spend more than 50% of their time on toil, with at least half their time going to engineering projects that eliminate future toil or add capabilities to services.
Why 50%, and not just "as little as possible"? Because a vague goal is no goal. Once it's a measurable line, overruns become visible, someone owns them, and they trigger action: adding people or cutting load. Google is emphatic about controlling toil because it spells out exactly what unchecked toil costs:
- Career stagnation. When engineering time gets squeezed out, growth slows or stalls. Unpleasant work is worth doing when it's unavoidable and high-impact, but nobody builds a career on repetitive manual work.
- Morale and retention. Everyone has a toil tolerance, and past it comes burnout and resentment. When toil overflows, the first people to look elsewhere are usually a team's strongest engineers.
- Eroded identity. SRE is fundamentally an engineering organization. Once a team drowns in toil, development teams start offloading ops work that should stay with them, and others begin to expect SRE to absorb it. That's a hard slope to climb back up.
Statistically, the biggest source of toil is interrupt-driven work, followed by on-call. The former is mostly non-urgent, service-related interruptions; the latter is urgent incident response. Google's rule of thumb: an SRE team needs at least six to eight people to keep on-call toil low. Without the headcount, rotation can't spread out, and you inevitably degrade into "duty without rotation," the same people, always on.
Outalator: the tool's job is to make the incident the unit
Back to the original question. Google's internal on-call tool is Outalator, where SREs manage the full lifecycle of alerts on one centralized platform. Its core capabilities are notably restrained:
- Alert grouping. Multiple related alerts collapse into a single incident, and SREs work at the incident level rather than chasing individual alerts. This step alone cuts a huge amount of duplicate notification and duplicate work. It's the root of noise reduction.
- Labels. Incidents get labeled with context, making it easy to filter, report, and review by label.
- Analytics. It analyzes alert-volume trends, response efficiency, and resolution efficiency across dimensions like team, person, service, and data center, so the team can see, from above, where on-call is weak.
- One-click handoff and reports. Select a set of incidents and hand their titles, labels, and key notes to the next on-call engineer by email, and handoff becomes effortless. A "report mode" supports the weekly production reviews many teams run.
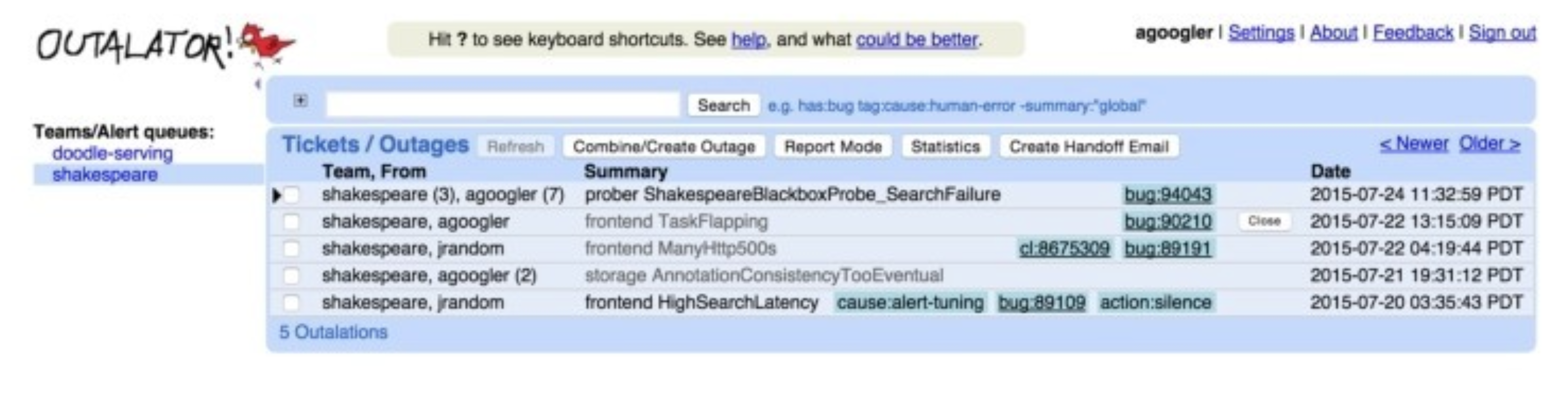
Outalator does nothing flashy. Everything it does is the plain work of collapsing alerts into incidents and letting people collaborate and review. A good on-call tool doesn't deliver reliability; it gives people the capacity to deliver reliability. The next section reinforces the point.
Datadog: writing "sustainable" into the rotation rules
If Google SRE gives us the conceptual frame, Datadog offers a more operational rotation playbook. As a leader in observability with very high availability demands on itself, Datadog's on-call practice is quite mature.
Several of its scheduling rules are worth copying outright:
- A floor on group size. Ideally six to eight people per rotation; if you truly can't, scrape together three to four, the minimum for a sustainable schedule. This matches Google's six-to-eight line exactly. Rotation works by dilution, and no process can rescue a roster that's too thin.
- A ceiling on shift length. Shifts typically run 8–12 hours, with workload, vacations, and swaps all folded into scheduling rather than set-and-forgotten.
- On-call means only on-call work. The engineer on duty focuses on alerts, checks, alert rules, and runbooks, not new feature development. Simple as it sounds, this institutionally recognizes that being on-call is a job, not something you do on the side.
- Frequency in the sweet spot. Too often and people burn out; too rarely and they lose any incentive to improve the process. It's an easily overlooked balance.

Beyond scheduling, Datadog invests in two places that are blind spots for many teams:
Real support for the person on duty. Throwing someone in with no training and no materials is irresponsible. Beyond tooling, Datadog runs a primary-and-backup pairing: if the primary sleeps through a page, the system notifies the backup; if the backup can't cover, it escalates to the direct manager. This safety net keeps "nobody answered at 3am" from turning into a real incident.
Managers in the rotation, too. Datadog puts direct managers on the schedule, partly to set an example, partly so managers feel the heat themselves. Only by truly experiencing on-call pain does a manager have the motivation to improve the process and tools. Managers who detach from the front line slowly lose touch, and the on-call process rots. It's a plain but remarkably effective corrective.
Reading the two together
Side by side, Google and Datadog point to the same conclusion: how well you run on-call doesn't hinge on what tool you bought, but on whether you treat it as a real thing to be designed, measured, and continuously invested in.
- Culture: people first, long-term outcomes, and an honest acknowledgment that on-call is a drain that deserves compensation and protection.
- Mechanisms: groups of six to eight, sustainable schedules, clear backup and escalation chains, managers on duty, and a hard cap of 50% toil.
- Tools: group alerts into incidents to enable collaboration, handoff, measurement, and review.
Of these three layers, tooling is the easiest to close. Culture and mechanisms are the real barriers.
How to put this to work
Copying Google's model wholesale is unrealistic for most teams. The line between on and off the clock blurs easily, and "duty without rotation" becomes routine; planning is driven by short-term goals, and technical debt piles up; in many companies the SRE-to-developer ratio approaches 1:100, making a six-person SRE group nearly impossible. These are structural headwinds, and there's no point pretending otherwise.
But "can't copy the whole thing" doesn't mean "nowhere to start." Begin with the cheapest, fastest-payoff moves.
First, establish measurement. Without measurement, there's no improvement. An ops lead sees "too many alerts, an exhausted team," but can't see the actual workload of alert handling, so they can't justify more headcount, can't see what to optimize, and the situation only worsens. A basic on-call dashboard should at least include:
- Noise-reduction ratio: the compression ratio after grouping; higher is better.
- Response ratio: the share of alerts that get acknowledged, a proxy for whether alerts are actually useful; higher is better.
- Total alert volume: alerts per window; lower is better, and SLO-based alerting can cut it sharply.
- MTTA (mean time to acknowledge): reflects handling efficiency and team pressure; keep it healthy, since chronically low can also mean people are being squeezed dry.
- MTTR (mean time to resolve): reflects observability, infrastructure, and understanding of the business; faster is better.
Once you can see these five steadily, decisions like "add people or fix the alerts" and "which alert to delete" finally have a basis.
Second, make the rotation sustainable. Can't field six people? Hold the line at a minimum of three or four, cap shifts at 8–12 hours, and define a primary-backup pair plus escalation to a manager. None of this needs extra budget, only that the rules get written down and followed.
Third, on tooling, you have ready options today. Outalator was never open-sourced, but comparable products now exist. They ingest alerts from all kinds of monitoring systems on one platform, do grouping and noise reduction, acknowledgment, escalation and assignment, and schedule management, all wired into IM and a mobile app, putting what Google and Datadog built into your hands.
Flashduty is built by the team behind the open-source monitoring tool Nightingale. It connects to mainstream monitoring systems and IM platforms and is simple to adopt. If you're weighing options, see the current Flashduty vs. PagerDuty comparison.
Tooling is only the start. Collapse alerts into incidents, put the metrics on the table, and make the rotation sustainable. Get those three right, and "running on-call like the best companies do" stops being a slogan.