On-call is a term that came out of the Western tech world; there's no perfect Chinese equivalent, the closest being "duty" or "standby." But anyone who's actually done it knows it's far more than "set up a rotation and answer the phone." A real On-call system is a full pipeline, from the moment a monitoring alert fires through acknowledgement, handling, and the eventual retrospective. Do any one stage sloppily and the whole experience falls apart.
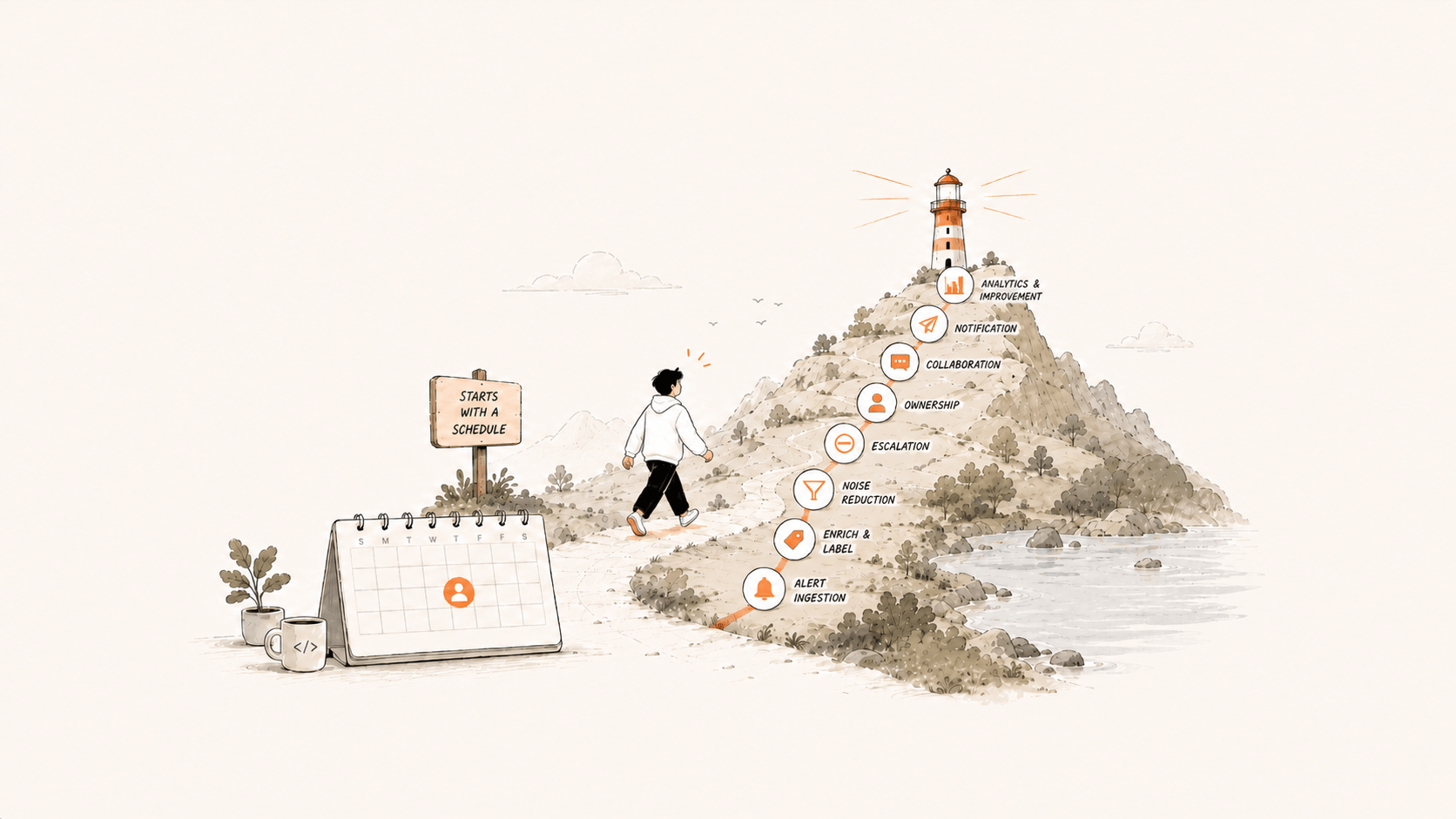
The diagram below lays out every key stage of that pipeline. This piece won't read you definitions one by one (there are plenty of those online already). Instead, it walks the diagram and explains, for each stage, why you need it, how far is far enough, and where the traps are.

Integration: get every alert into one place
The first step is to funnel alerts scattered across different monitoring tools into a single platform. Almost every monitoring system supports Webhooks, so an On-call platform only needs to adapt to each source and expose the right Webhook endpoints, which gives users the lowest possible setup cost.
Some less open systems only send email, no Webhook at all. If the platform can ingest those emails and parse the body into a structured alert, that's a fallback. The trade-off: email parsing is inherently fragile. A small template change on the sender's side can break it, so it's a last resort, not a first choice. If a Webhook is available, don't go through email.
Label enrichment: the richer the fields, the faster the response
Many monitoring tools emit "bare" alerts: just host name, metric, and threshold. An engineer woken at 2 a.m. can't judge blast radius from those few fields.
If the platform can pull in external metadata (a CMDB, say) and fill in the fields on the way in (which business this host belongs to, which environment, who owns it), those enriched labels can both drive more automated dispatch and let an engineer gauge severity at a glance. The baseline: enrich the fields that directly affect "should we wake someone, and whom." Piling on labels nobody reads just adds noise.
Grouping and noise reduction: collapse N alerts into a handful
This is one of the core capabilities of any On-call product. A single large outage can fire hundreds of alerts at once; notify them one by one and the responder's phone melts down, which actually slows the response. The goal of grouping is to collapse a burst of similar alerts into a handful of incidents, and notify only at the incident level.
Grouping can be rule-based or semantic-similarity-based, and it can span data sources: an alert from Zabbix and one from Prometheus can land in the same incident if they're "similar." Beyond mass-instance outages, flapping alerts (firing, recovering, firing again) are another classic case. Group them by a shared label into one incident and the frequency drops sharply.
Suppression: use it sparingly, don't lean on it
Suppression isn't the same as grouping. Grouping merges similar alerts; suppression introduces a dependency, where a high-severity alert suppresses low-severity ones, or an infrastructure-layer alert suppresses service-layer ones. If a data center loses network, there's no point alerting separately on every service inside it.
Suppression sounds great, but here's the trap: those dependencies are costly to maintain and hard to explain. The moment a rule silently swallows an alert that should have fired, debugging it is miserable. So suppression fits a few cases with clean, stable boundaries; don't lean on it heavily at scale. If grouping can solve it, don't reach for suppression.
Schedules: stop interrupting the whole team
The point of a schedule is to keep the whole team from being interrupted repeatedly, while still guaranteeing the right person is online at any hour. On-call genuinely helps engineers grow, but it's tedious and full of night wake-ups; run people on it indefinitely and their health gives out. So it has to rotate.
A few dimensions you can't dodge when designing rotations:
- Fairness: keep the load even, so no one is always on duty over weekends or holidays.
- Flexibility: allow planned or last-minute swaps to cover leave and time off.
- Rotation period: hourly, daily, weekly, or monthly, whatever matches the business rhythm.
- Roles: usually a primary and a backup. The primary is the first responder; when they're overloaded or unresponsive, the issue escalates to the backup.
- Handoff notification: shift changes need a clear notification mechanism. Ping the next person N minutes ahead, or broadcast once at a fixed time each day.
A word on the economics: some engineers are happy to take On-call, since it can mean overtime pay or time off in lieu. But put everyone on it and the subsidy bill becomes unbearable. So rotation is also a cost-saving move: fewer people on duty means a smaller bill.
Acknowledgement, escalation, collaboration: give every alert an owner
Acknowledgement: in theory, every alert should be acknowledged. Run the logic backwards. If an alert fires, nobody acknowledges it, and nothing bad happens, it was meaningless and should never have been sent. MTTA (mean time to acknowledge) is the usual way to quantify this.
Escalation and reassignment: drawing clear escalation paths for each severity ahead of time noticeably lowers a responder's stress. Escalation can be manual or automatic. For example, if an alert goes unacknowledged and unrecovered for over 30 minutes, auto-escalate to a manager or backup so someone always catches it.
Here's a mature tiered-response pattern worth spelling out, one that many 7×24 teams run:
| Tier | Who's notified | Trigger |
|---|---|---|
| L1 | The on-shift front-line responder (by rotation) | The moment an alert fires |
| L2 | Track leads (dev / reliability / ops) | L1 didn't respond in time, or the issue is escalated |
| L3 | Incident commander / business owner | A major incident still isn't contained |
In practice, you build one schedule each for L1/L2/L3, then set three stages in the dispatch policy, binding each stage to its schedule. "Call this one first, then the next if there's no answer" runs itself, and no one has to drag people in by hand at 3 a.m.
Collaboration: you can pull relevant people in at any point during handling. The key is to notify them accurately and promptly, and to preserve the full handling process and timeline so latecomers can grasp the whole picture instead of repeatedly asking "where are we now?"
Notification: delivery experience is everything
The best alert is worthless if it doesn't reach the right person, or if they can't act on it. Western teams lean heavily on Slack; it's practically the operating system of collaboration. In China it's WeCom, Feishu, and DingTalk. These IM tools all support building apps, and being able to acknowledge, close, reassign, and handle alerts right inside an IM card is the key to a good On-call experience.
Picture this: an alert fires at night, but you can tell at a glance it doesn't need hands-on work right now. If you can pull out your phone and clear it inside IM in a few taps, you don't have to get up and boot a laptop. That one detail is a real, tangible boost to morale.
Analytics: no data, no governance
The biggest payoff of routing all of a company's alerts into one platform is being able to slice the numbers. Compression rate, MTTA, MTTR, acknowledgement rate, alert volume: these are the key efficiency metrics. Cut them by business, team, and individual to find the weak spots.
A more practical use is governing the alert rules themselves: rules that fire constantly usually signal a bad rule, one that burns phone-and-SMS money, annoys engineers, and does nothing for reliability. Fix the ones worth fixing, delete the rest.
More important than tooling: make alerts worth waking up for
Everything above operates after an alert has already fired. But the most cost-effective noise reduction happens before, by governing alert rules at the source:
- Every alert should be actionable, tied to a concrete mitigation step or SOP. If an alert is just a "heads-up" that requires no one to do anything, it's almost certainly redundant. If you're genuinely afraid of missing something big, have it auto-create a ticket you scan periodically, instead of calling, texting, or messaging someone.
- Alert on outcome metrics, not cause metrics: for an HTTP service, success rate and latency are outcome metrics, the ones to watch. CPU utilization is a cause metric: put it on a dashboard for observability. If a cause metric is unhealthy but the outcome metric is fine, business isn't affected yet, so there's no need to wake anyone.
The reason so many teams accumulate ever more alerts is that the first question in every retrospective is "were the alerts complete?" So to avoid blame, engineers would rather over-add rules than under-add. Over time that builds a pile of useful and useless rules alike, new hires can't stand it and leave, and the team slowly drains.
In the end, good On-call is half product and half mindset. If front-line engineers are suffering while leadership hasn't even noticed, communication is a dialogue of the deaf. Taking this seriously can, at times, lift a team's morale more than a raise.
Flashduty turns every stage in that diagram into a working capability: multi-source integration, grouping, schedules, escalation, two-way IM delivery, and analytics dashboards. If you're building or rebuilding your On-call system, this is a good place to start: Flashduty.