How a small team with no dedicated product manager keeps its docs from falling behind
Flashduty's on-call scheduling has a feature called Fair Rotation. Turn it on, and the system automatically adjusts the rotation order so the same person doesn't always draw the weekend shift. The frontend code looks like this:
<div className='flex items-center'>
{t('Fair Rotation')}
<Tooltip>
The system automatically adjusts rotation order to ensure
each member gets on-call shifts across different time periods.
</Tooltip>
</div>
<Form.Item name='fair_rotation' valuePropName='checked'>
<Switch size='small' />
</Form.Item>The feature was built with care. Frontend and backend both shipped it. It runs in production. People use it.
And there wasn't a single word about it in the docs.
Unless you happened to be editing a rotation rule and noticed an unassuming toggle, you'd have no idea the feature existed. This is what documentation drift looks like: not a catastrophic outage, just one small gap after another until users stop trusting the docs.
We found this gap because we built a system to find it for us. This post is about three things: why we did it, how we did it, and how you can build one too.
Why docs always fall behind
We're building an AI support agent. It answers users' questions by reading our docs. When the docs have gaps, the AI can't answer. When the docs have errors, the AI answers wrong. Doc quality used to mostly affect human readers: an engineer woken at 3 a.m. by an alert, digging through docs to chase down a problem, cursing when they couldn't find it. Now it determines the quality of the AI's answers. Garbage docs in, garbage answers out.
The problem is, nobody writes the docs.
Flashduty has no dedicated product managers. The engineers are the product managers: analyzing requirements, writing the PRD, building, testing, deploying, handling customer feedback, all the same people. "Keep the docs in sync" isn't in anyone's job description. The person who spent two weeks building Fair Rotation does not want to spend another day writing it up. They want to build the next feature. So the docs don't get written. The answers end up scattered across Feishu, WeCom, and DingTalk chat logs, and never make it into the docs.
We're not exactly small: 12 product modules, 20-plus microservices, bilingual docs in Chinese and English, hundreds of pages. Every PR that merges can quietly turn some description in there into a lie. Manual review is possible in theory; in practice, nobody ever does it.
The situation was clear: engineers don't want to write docs, users need docs, and the AI support agent's quality depends entirely on the docs. "Please remember to update the docs" doesn't solve that. If people can't be relied on, then stop relying on people.
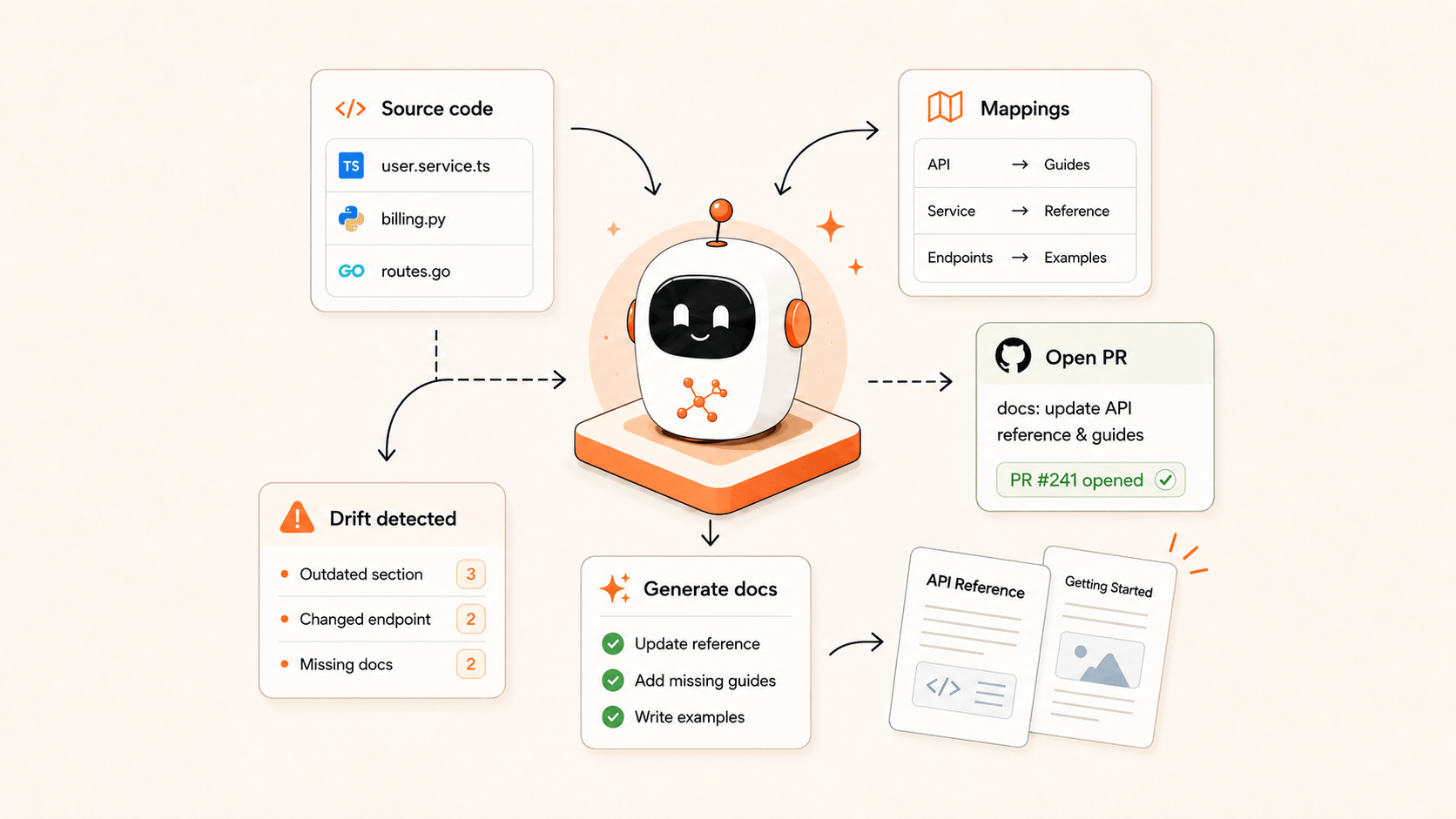
What we built
We built a Claude Code skill, a reusable AI agent an engineer can run with a single command or schedule to run on its own.
The core design idea: a YAML mapping file that pairs each docs page with the source-code paths behind it. The agent knows where to look because we told it which code corresponds to which doc. Without that mapping, it either casts too wide a net (drowning in unrelated internal code) or misses the changes that matter.
flowchart TD
T1["Code push / scheduled job"] --> SCAN["Scan source repos"]
T2["Manual trigger"] --> SCAN
SCAN --> DIFF{"Mode?"}
DIFF -- "diff" --> GD["Read git diff\nFind new routes, toggles, defaults"]
DIFF -- "audit" --> WF["Walk frontend code\nInventory every feature"]
GD --> XREF["Cross-reference against docs"]
WF --> XREF
XREF --> FIND["findings.yaml"]
FIND --> AUTO{"Auto mode?"}
AUTO -- No --> HUMAN["Engineer reviews\nRemoves false positives"]
HUMAN --> FIX
AUTO -- Yes --> FIX["Read source\nGenerate docs (ZH + EN)"]
FIX --> PR["Open PR"]
PR --> REVIEW["Engineer reviews content"]
REVIEW --> MERGE["Merge"]Two modes:
Diff mode asks: "What changed in the last two weeks?" The agent reads the git diff across every linked repo and looks for doc-relevant signals:
- New API routes or endpoints
- New UI toggles or form fields
- Changed defaults or validation rules
- Removed or renamed features
Every signal gets cross-referenced against the existing docs. Anything already covered is skipped; anything not covered is recorded as a finding. This is routine upkeep: catch drift before it piles up.
Audit mode asks: "Does every feature have docs?" This one is more thorough. It first walks the frontend code and inventories every user-visible feature: every page, form field, toggle, and dropdown option. Then it checks coverage one by one.
Why start from the frontend? Because the frontend is the honest expression of what the product can actually do. The backend has internal endpoints, reserved fields, customer-specific logic, and reserved enum values that never show up in the UI at all. What the frontend exposes is what users can actually see and touch.
Audit mode also does an accuracy check: it extracts mechanically verifiable facts from the existing docs, such as field names, default values, navigation paths, and validation rules, then compares each against the code. The docs say the rotation period supports "day, week, custom"; the code supports hour, day, week, month. That's a finding.
Both modes emit a structured findings file. Then comes the fix phase: the agent reads the source code behind each finding and writes complete documentation in both Chinese and English, including paragraphs, tables, and configuration steps, then opens a PR. No placeholders, no TODOs. An engineer reviews the content and merges.
What we found
The big picture first: after running both diff and audit modes, the agent produced 20 PRs, more than 9,000 lines of new documentation, across 370-plus files and hundreds of findings.
The first run was diff mode: /doc-review --mode diff --since "1 month". It looked at just the last month of code changes and produced this PR. That single run surfaced 21 gaps, touched 33 files, and added over a thousand lines of docs across the two languages. Here are a few representative ones:
| Finding | What happened |
|---|---|
| Fair Rotation | The story this post opened with. Complete feature, zero docs. |
| Permission model | We moved from flat permissions to scope-based permissions; the docs still described the old model. |
| Nagios integration | The whole integration was running in production. No docs. |
| Team management | The team detail page had no docs for adding members, removing members, or leaving a team. |
| RUM source maps | The upload flow for Android ProGuard and iOS dSYM had been live for months and was never written up. |
| Workspace navigation | The UI switched from tabs to a sidebar; the docs still described the old layout. |
None of these are obscure features. They're real features that real users couldn't find in the docs.
21 gaps already surprised us. Then we ran audit mode, the full-frontend feature inventory. It came back with more than ten times that. That settled it: this went from a one-time cleanup to a weekly routine.
Build your own
You don't have to start from scratch. Claude Code has a skill-creator that generates a skill from a description. Here's a working prompt template:
/skill-creator Create a doc-review skill that cross-references
source code against documentation to find documentation drift.
Context:
- Docs repo: company-docs (Docusaurus, English only)
- Source repos: billing-service (Go), web-app (React), api-gateway (Go)
- Docs structure: docs/ with subdirectories per product area
- Key concern: new features ship without doc updates
The skill should have two modes plus a fix phase:
1. Diff mode: scan recent git changes for doc-relevant signals
2. Audit mode: walk frontend code to inventory features, check coverage
After either mode, a fix phase generates complete documentation and opens a PR.skill-creator will generate the mapping config, the prompts, and the wiring that ties it all together. Standing up the skeleton is fast, about an hour. Tuning it until it is useful takes longer; it took us roughly four rounds to get the signal-to-noise ratio where we wanted it. The useful part is the design principles you encode into the prompt. Here's what we learned the hard way:
-
Map modules to repos. A single YAML file linking each docs page to its source-code paths. Without it, the agent either drowns in unrelated code or misses the changes that matter. This is the skeleton of the whole system.
-
Inventory from the frontend. The frontend defines the boundary of user-visible features. The backend has internal endpoints, reserved fields, reserved types. Start from frontend components: pages, forms, toggles, dropdowns. Use the backend only to fill in details about features the frontend has already exposed.
-
Judge with a product manager's eye. Spell it out in the prompt: "Decide, like a product manager, what belongs in the public docs." Only record features a user can actually operate in production. Skip test tooling, debug panels, test harnesses, internal admin functions, and customer-specific logic.
-
Only check mechanically verifiable facts. Check field names, default values, API routes, validation rules. Don't try to verify prose that describes behavior; that needs human judgment and has a high false-positive rate.
-
The frontend is the authority on constraints. The backend says the cap is 100, but the frontend form only allows 50. What the user sees is 50, so the docs should say 50. Only record a finding when the docs contradict the frontend.
-
Generate complete content, not placeholders. The fix phase must read the source and write real documentation: paragraphs, tables, configuration details. The reviewer's job is to polish the prose, not fill in the blanks. This is the difference between a useful PR and a pile of TODOs.
-
Two phases with a human gate. Analyze → findings file → human removes false positives → fix. The findings file is the checkpoint between the two phases. Once the signal-to-noise ratio is good enough, you can use
--autoto skip the findings review, but the final PR is still reviewed by a human before it merges.
The first run will be messy, guaranteed. Start with --dry-run, look at the findings list, and adjust the prompt. Use skill-creator to iterate: feed it what went wrong and let it refine the prompts and mapping config.
Once it's tuned, you can automate it. We run diff mode weekly via a cron job; if there are findings, it opens a PR automatically. Engineers only review the PR. Detection, writing, and submission are handled by the system.
What we learned
Documentation drift is not fixed by asking engineers to become better writers. It is fixed by making the gaps visible and giving engineers a complete PR to review. Reviewing that PR takes five minutes. Writing a doc from scratch starts at half a day, so it never makes it up the priority list.
We thought our docs were pretty good. The actual results said otherwise. Your docs probably have gaps of a similar scale; you just don't know it yet.
AI is good at the tedious part: reading hundreds of files, cross-referencing field names, checking whether a default value matches the code. It is not good at judging whether a feature is worth documenting, or whether a sentence will confuse a user. The PR still needs an engineer's review. But the grind is gone.
One practical tip: if your product has a web UI, scan from the frontend code, not the backend. Our first two iterations were backend-first, and we drowned in internal tooling that nobody should ever document. The frontend is a natural filter. If your product is API-first, such as a CLI tool or an SDK with no UI, pick a different entry point. API route definitions or CLI command registrations make a good starting point.
What's next
That Fair Rotation toggle is documented now. So are the hundreds of other findings. But this is only the start.
We're working on two things. First, wiring diff mode into CI: detect doc drift the moment code merges, run doc checks like tests, and catch a gap when it is created instead of waiting for the weekly scan. Second, extending detection to the API docs. The system currently starts from the frontend, but our Open API needs the same coverage guarantee.
Our docs live at docs.flashduty.com. Engineers now review doc PRs instead of writing docs from scratch. The shape that worked for us was simple: one hour to stand up the skeleton, four rounds to tune it, then a five-minute PR review each week.

